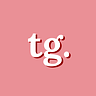

Attention is all I need

This past weekend I found myself in Toronto having drinks with a friend who just started their new job at Cohere.ai. Cohere is a startup building a set of APIs that generate and comprehend human language, abstracting the work of building huge, world class natural language processing models away from regular mortals. It didn't take long to be starstruck by the team that was building this company- It was founded by 3 AI researchers, one of whom was literally on the paper that introduced a new model architecture that blew existing neural nets out of the water for language processing. Cohere's product lead wrote a blog post describing the innovation that is among the top 3 Google Search results when you look up transformer models. Since I needed to say more, I’ll casually drop that Cohere is backed by AI heavyweights such as Geoffrey Hinton (2018 Turing Award Recipient) and Fei-Fei Li.
This team made it clear to me that Cohere was doing something cutting edge in natural language processing, but at the time I didn't know what it was. I was even skeptical that there was still a market appetite to converse with machines. I kept thinking about NLP through the limited lens of its existing commercial applications such as customer service chatbots. Do you remember when AI chatbots were considered the greatest innovation ever around 3 years ago? We’ve now left that period of time with only a few unicorns and startups still driving toward a vision of a fully automated customer service agent. Contrast chatbot companies or even IBM Watson against the size of Tesla, and there's no question between NLP or autonomous driving research which seems like a better investment.
I spent a few days afterwards immersing myself in the lore of recent machine learning milestones, and I can’t believe how tiny my worldview was. Holy hell. Not to hype up something that’s apparently already overhyped, but man, why is this still mainly used in chatbots?
Save the eye rolls you’ve cued for me and hear me out. This week I wanted to cover the types of use cases that have gotten people really excited and why language processing models have gotten [what feels like] exponentially better in just the last decade. I was particularly curious why applications of these advanced models aren't yet widely used, so I'll also share why it’s been a challenge to get these pre-trained models in the hands of the masses and why I believe Cohere is focused on just the right problem.
Here's what I missed
In May 2020, Open AI released the third edition of their Generative Pre-Trained Transformer (GPT) model. As the name suggests, it is able to generate output text based on an input, it is already trained on language data so you don't need to do it yourself, and it uses a transformer neural net model architecture. In a landscape where the biggest names in AI are engaged in an arms race to produce the largest model, GPT-3's release hilariously eclipsed the next largest model (by training parameters) by tenfold.

Open AI was really like:

The hype, even as I'm reading about this from a year out, was palpably mental. Every white collar tech worker had an existential crisis about their job security. After all, demos like these were going viral:
GPT-3 writing code:

GPT-3 doing graphic design:
GPT-3 passing 3 out of 4 of its college papers:

See, this created a bit of dissonance for me as I worked at a conversational AI startup 3 years ago and it wasn't easy to train a model on just retail banking queries. How were models now training on 175 billion parameters? Wouldn't that take literally forever? Did we even have computers fast enough to generate outputs as fast as these demos were showing?
It turns out that a breakthrough technology for sequential data processing models (like language) was introduced in 2017. Up until that point, the model of choice for language processing tasks like translation and comprehension was a recurrent neural network- It was the model used in Siri! RNNs excelled at training on and predicting sequential data, like the next word in a sentence. However, they had two widely known downfalls:
Parameters needed to be fed into the model sequentially instead of all at the same time, which meant RNNs took a long time to train
Because of the sequential nature in which data was stored, it was better at recalling parameters it recently learned vs parameters it learned more inputs ago
In 2017, a team of researchers at Google Brain released a paper introducing a new model architecture called the transformer neural network meant to address these issues with sequential models. To train a transformer, you would input a sequence and that entire sequence would be encoded based on each individual word's relationship to each other. Transformers didn't care about how long ago a word appeared in a sequence as its memory would map word associations closely together. Transformers enabled us to train way bigger models than ever before, which is what set us on the arms race path we see today.
It's clear this technology is capable of way more than how it’s commercially applied today. Why aren't its applications widely used in everything we do yet?
Parenting 101: Growing language models

It's hard not to jump to surface level conclusions about why cutting edge language models aren't used beyond summarized Google Searches and finishing your sentences in email. I immediately concluded that perhaps on the demand side, it was just hard for business people to figure out how they could use a classification and generation for use cases beyond marketing copy. I realized this wasn't the case when I saw the excitement around the prototypes I showcased above- Prototypes that could be written by anyone who knew how to hit an API. The biggest obstacle for people to build stuff is getting access to the GPT-3 APIs.
Perhaps, then, the issue was with the economics of supplying technology like this. Maybe it's too technically challenging to allow lots of people to use these models at scale. But Stella Biderman of Eleuther AI is working on building an open source version of GPT-3 and says it isn’t technically very difficult to replicate an AI model like it. "The barrier to creating a powerful language model is shrinking for anyone with a few million dollars and a few machine learning graduates. Cloud computing platforms such as Amazon Web Services now offer anyone with enough money the tools that make it easier to build neural networks on the scale needed for something like GPT-3." (source).
No, the barrier to widespread access to cutting-edge NLP right now isn't that we can't figure out what to build with it or that models can't support industry usage. The barrier is that we know that these models can do shitty, unsafe things and we haven't fully figured out how to mitigate those risks. The first firm to figure out how to safely deploy a multipurpose NLP API through manual and automated measures will dominate the market.


This brings me back to Cohere AI. I'm not affiliated with the company in any way, and a few days ago I was unclear how they were planning to differentiate in a sea of impressive models. Like Open AI, they've built a huge model and abstracted all the infrastructure and training into a set of APIs for anyone to build their own Google-level search engine and copy generator. However, I can now see one thing that does stand out to me: Their outward focus on figuring out how to make their technology safe.
Let's just look at the nav bars of some of the firms I mentioned that are developing these language models:

This isn’t deep investigative work, but Cohere is the only site to host a page about "Responsibility", second only to the page describing what its product does.
When I combed through API documentation, I was impressed to find how much work had gone into testing for safety and also including that transparency.
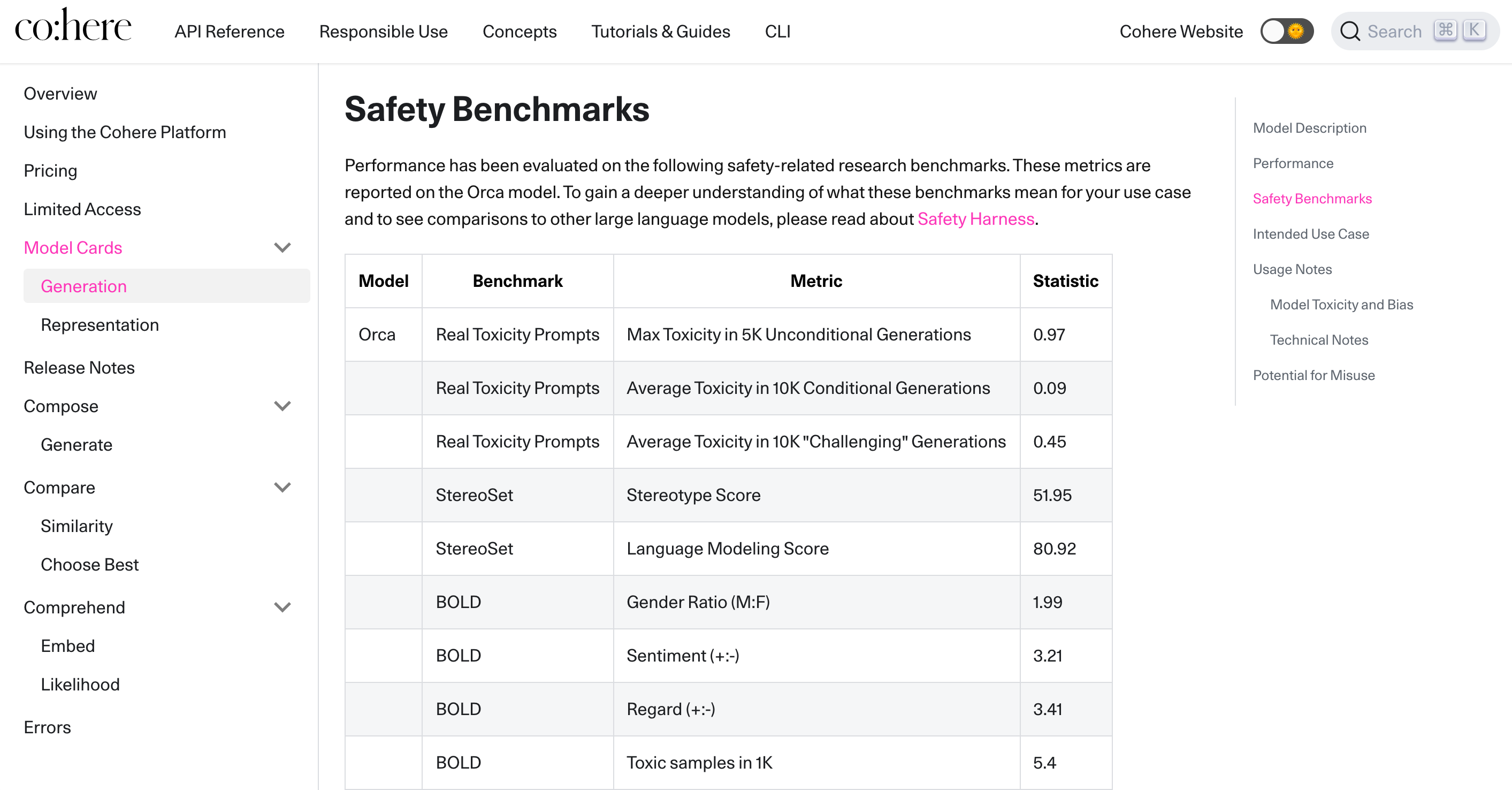
By contrast, Open AI has a page of best practices but no such information about how their model persons against safety benchmarks. The meme I found above suggests that their content filter might be fairly sensitive, but that’s just a guess.
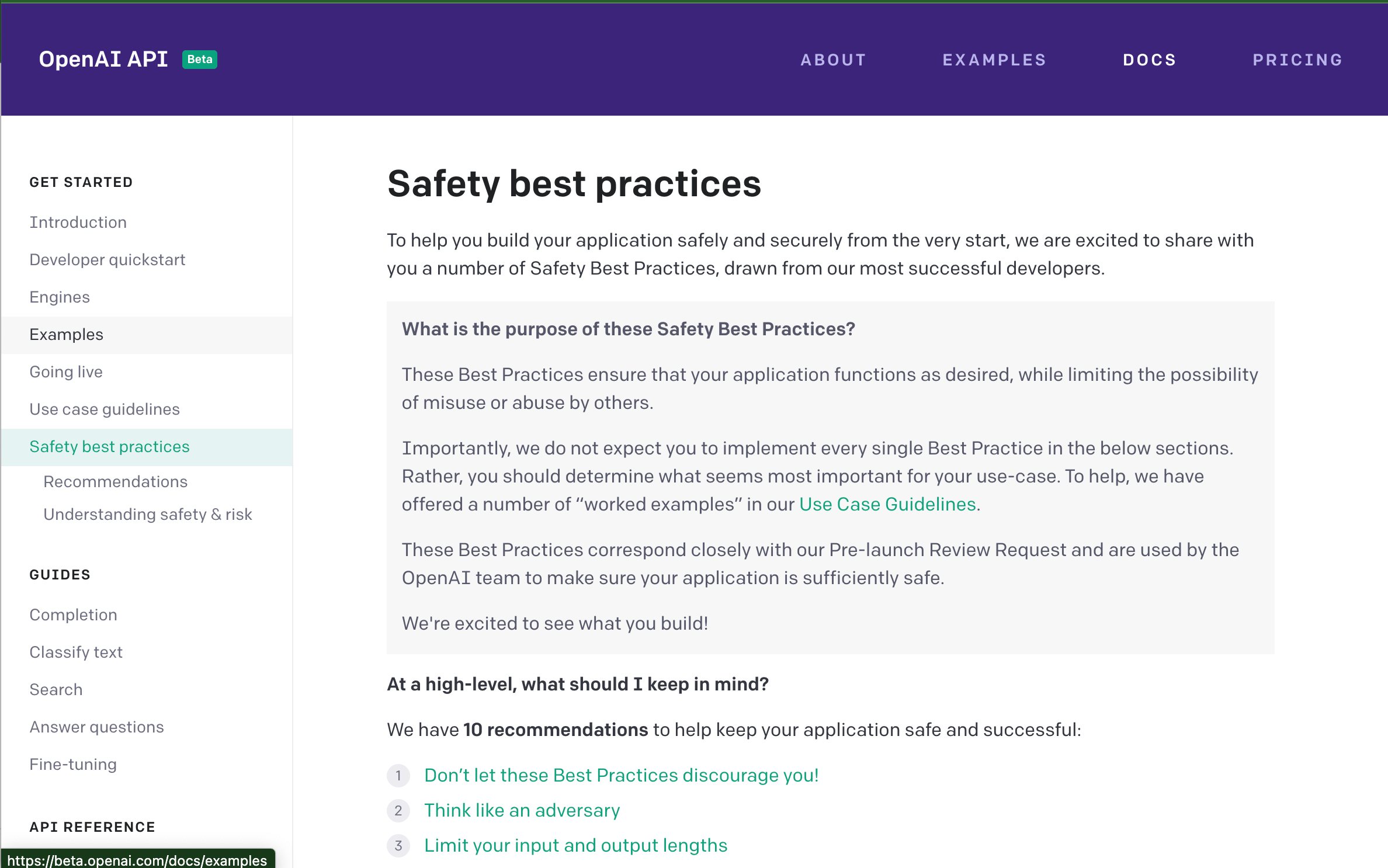
Finally, Cohere researchers are actively publishing papers about how they're making their models less harmful:


There is no existing playbook for deploying a general language technology to the public in a safe way, but Cohere seems to be tackling the problem head on by publishing research, enforcing their own accountability, and pushing potential customers to think about risks in a way I haven't seen from other firms like Open AI. By choosing to differentiate in this way, they can develop new technology to govern their own models and set industry standards for safe usage. Since this problem is an obstacle for every AI firm looking to monetize their models, Cohere stands a great chance of solving this problem first and dominating NLP as a service market.
As of now I’m not able to gleam much more about them from their online presence. I look forward to watching what they put out and how they help this space evolve. Huge thanks to my friend for bringing me onto this bandwagon- Consider giving me beta access? 🥺